相關(guān)推薦文章
發(fā)布時間:2015-06-09 發(fā)布者: 點擊:
首先我們得要知道robots文件時干什么的?存放的位置在哪里?
robots文件主要是告訴搜素引擎,網(wǎng)站哪些頁面可以抓取,哪些頁面拒絕抓取,下面我們看下幾個截圖!
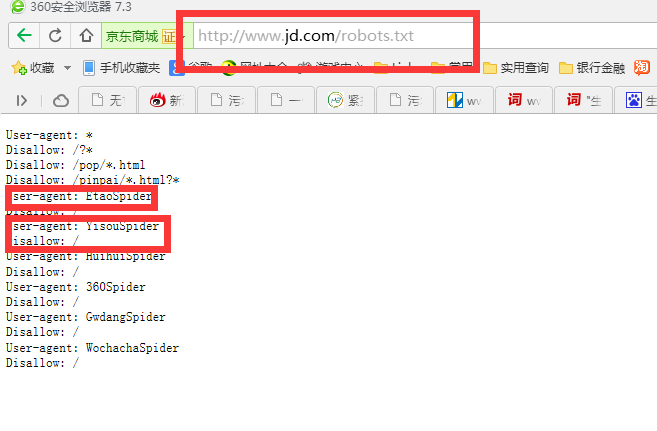
京東牛B吧,拒絕了360,一淘網(wǎng),
disallow的主要作用是拒絕某些指定的搜索引擎抓取我們不想讓他看見的頁面,作為企業(yè)站的我們肯定是希望搜索引擎來抓取我們那么這個disallow到底有什么具體應(yīng)用呢,其實我們可以用disallow拒絕404錯誤的地址頁面或者重復(fù)的頁面!
User-agent: * (聲明禁止所有的搜索引擎抓取以下內(nèi)容)
Disallow:/blog/(禁止網(wǎng)站blog欄目下所有的頁面。比如說:/blog/123.html)
Disallow:/api(比如說:/apifsdfds/123.html也會被屏蔽。)
Disallow:*?*(只要你的路徑里面帶有問號的路徑,那么這條路徑將會被屏蔽。比如說:http://xxxxx/?expert/default.html將會被屏蔽。)
Disallow:/*.php$(意思是以.php結(jié)尾的路徑全部屏蔽掉。)
Sitemap:http://xxx.com/sitemap.html 網(wǎng)站地圖 告訴爬蟲這個頁面是網(wǎng)站地圖
User-agent: * 允許訪問所有
Disallow: / 拒絕所有
Allow: /tmp 這里定義是允許爬尋tmp的整個目錄
Allow: .htm$ 僅允許訪問以".htm"為后綴的URL。
Allow: .gif$ 允許抓取網(wǎng)頁和gif格式圖片
更多搜索引擎體驗請點擊
啟凡首頁 | 公司簡介 | 設(shè)計案例 | 推廣案例 | 客戶評價 | 常見問題 | 新聞中心 | 聯(lián)系我們 | 人才招聘 | 付款方式 | 網(wǎng)站地圖 | 百度統(tǒng)計
咨詢熱線:18937652899 Email:qifan@zzqifan.com 傳真:0371-69180801
地址:鄭州市中原區(qū)萬達廣場西區(qū) 5號樓 3單元 1402室 版權(quán)所有:鄭州啟凡計算機軟件有限公司豫ICP備11009532號-1豫公網(wǎng)安備 41010202002058號
<fieldset id="gqtv0"></fieldset>
